LSTM源于Recurrent Nerual Network(RNN),RNN和全连接神经网络的原理并无区别,都是基于梯度下降的原则,只是在结构上有点区别,首先看一下RNN结构:
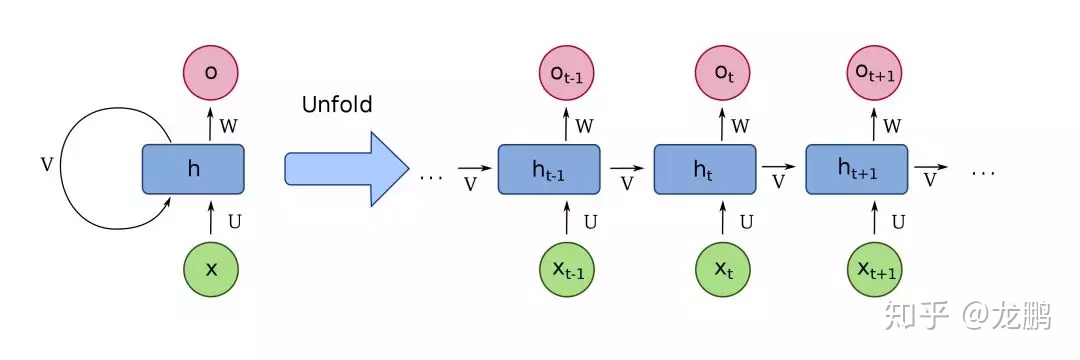
RNN有两个输入:
- 当前时刻输入xt,用于实时更新状态
- 上一时刻隐藏层的状态ht-1,用于记忆状态,而不同时刻的网络共用的是同一套参数$(U,W,b)$
- 全连接神经网络一般通过 反向传播(BackPropagation) 优化
- RNN通过BackPropagation Through Time(BPTT)优化,原理一样,只是这个需要考虑时间序列
- one to many:输入图像,输出描述图像的文本
- many to many:输入输出等长,在线作诗机器人
- many to many:输入输出不等长,Seq2Seq模型,在线翻译;另外还有Attention Mechanism,突出重点
- 经典模型:LSTM、GRU
RNN输入是有序的,可以模拟人类阅读的顺序去读取文本或者别的序列化数据,且通过隐藏层神经元的编码,上一个隐藏层神经元的信息可以传递到下一个隐藏层神经元,所以形成了一定的记忆能力,可以更好地理解序列化数据
RNN存在 梯度爆炸(Gradient Explode)和梯度消失(Gradient Vanish) 的问题。而且,在前向过程中,开始时刻的输入对后面时刻的影响越来越小,这就是长距离依赖问题。这样一来,就失去了 “记忆” 的能力,要知道生物的神经元拥有对过去时序状态很强的记忆能力。
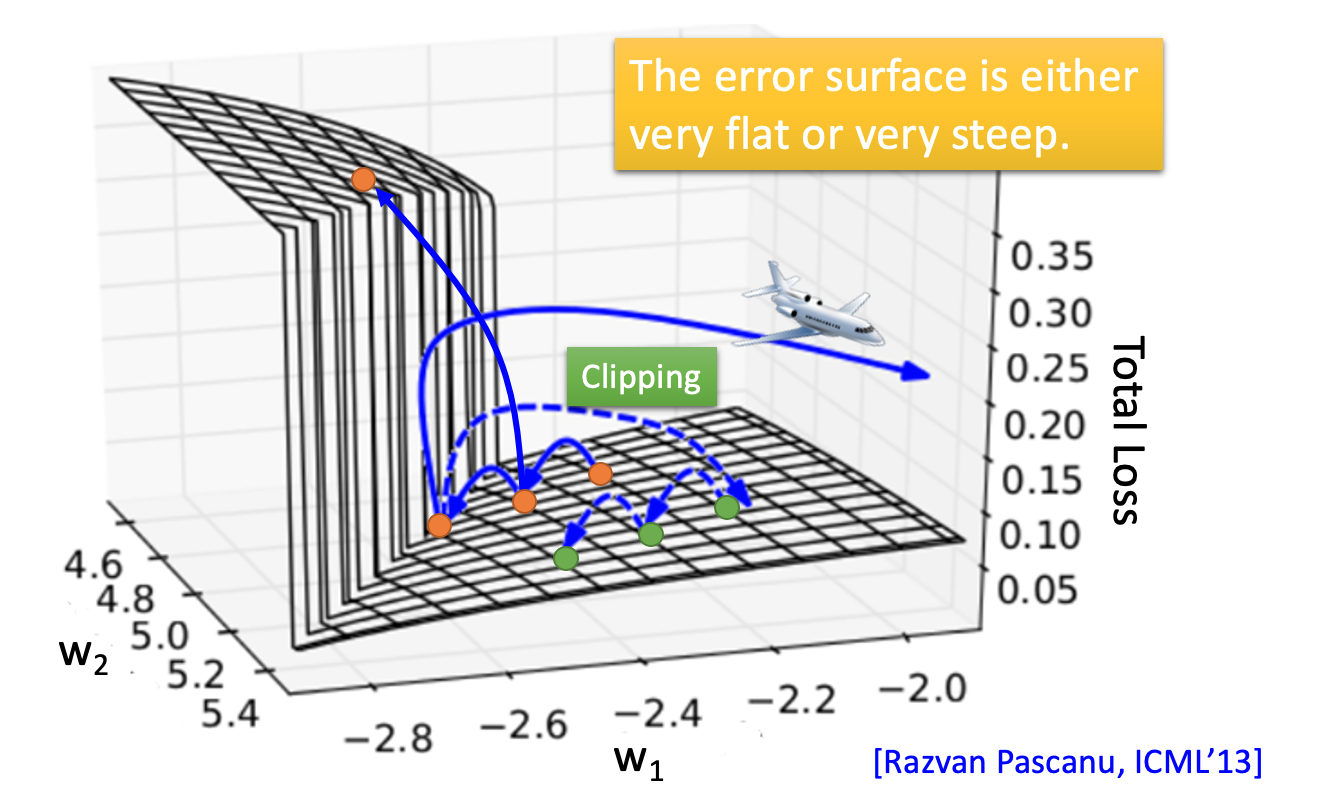
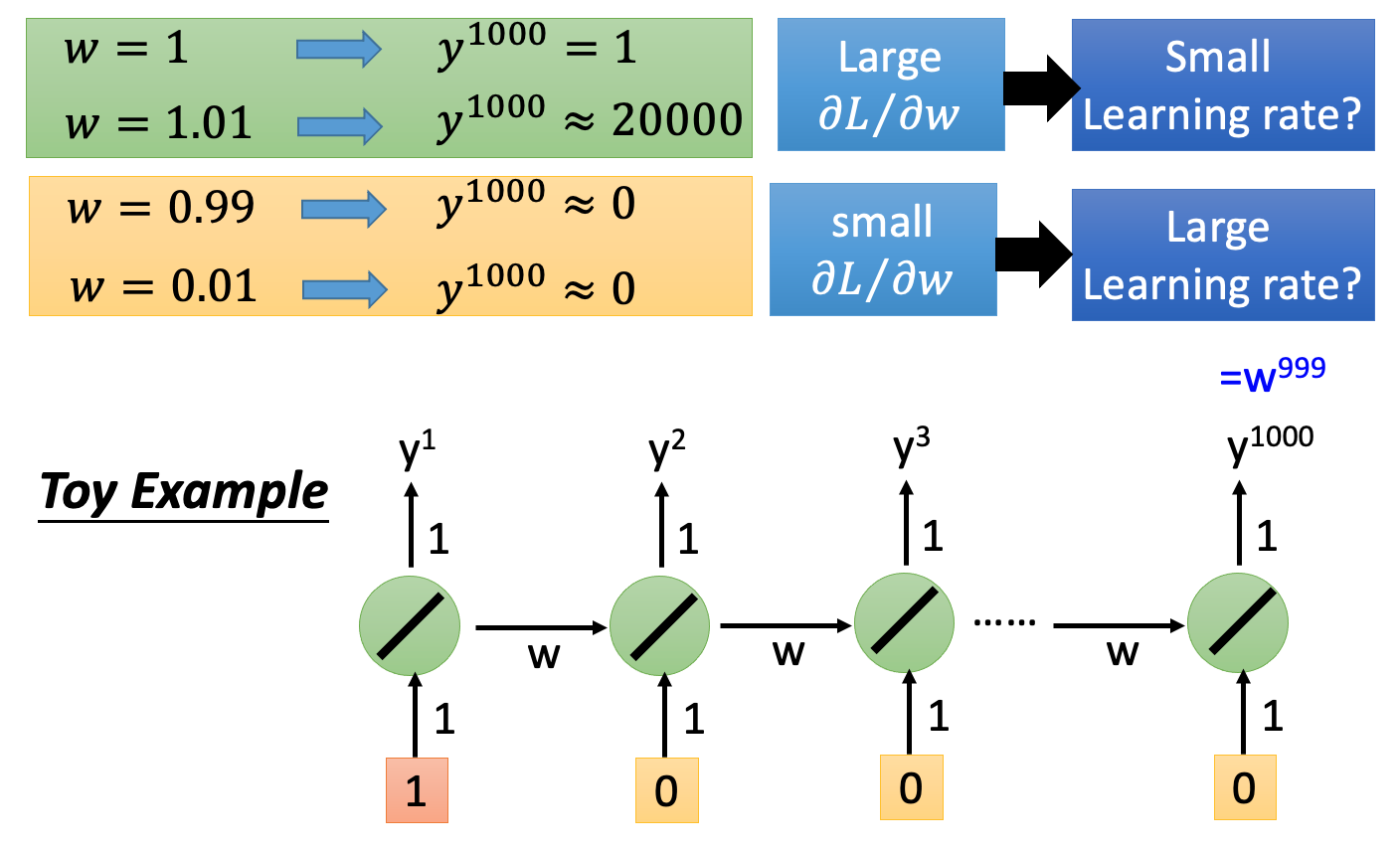
为了解决RNN的梯度消失的问题,提出了LSTM
- 三个门控信号:输入门、遗忘门、输出门
- 和RNN不同在于:LSTM有四个输入**($Z,Z_i,Z_f,Z_o$)**
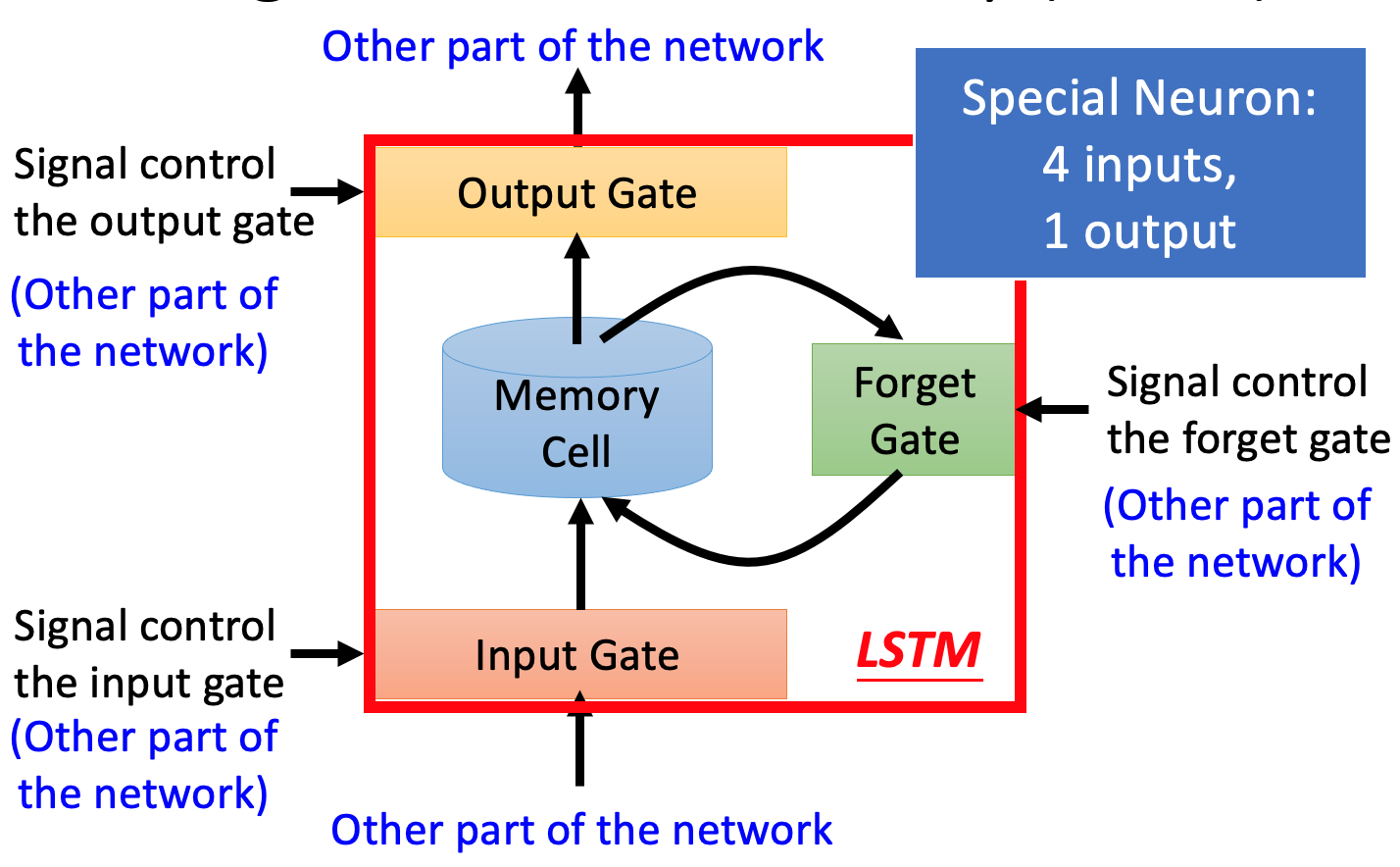
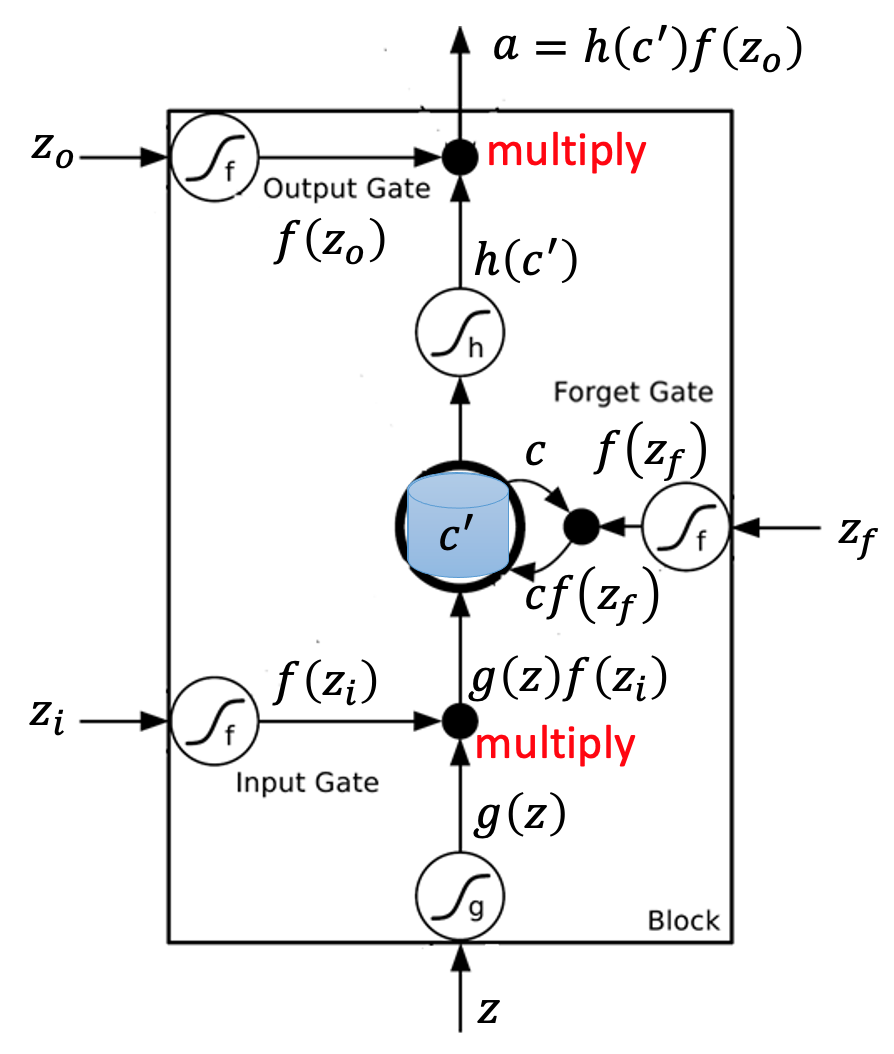
说明:
- 作用于$Z_i, Z_f, Z_o$的函数:通常是Sigmoid函数,即$\sigma(z) = \frac{1}{1+e^{-z}}$,让它们的输出在0~1之间
- Forget Gate:当$f(Z_f) = 1$时表示记住这个输入,反之表示遗忘
- 上右图中:$c'=g(Z)f(Z_i)+cf(Z_f)$
- 和四个输入相关参数是不一样的
为什么LSTM可以处理梯度消失呢?
- RNN中每个时间点memory里面的信息都会被”冲掉“,因为每个时间点neuron的output都会被放到memory里面去
- LSTM中memory里面的信息是和input相加的,如果memory受到的影响会直接存在,除非$f(Z_f) = 0$ 。所以一般确保给到Forget Gate给到的参数比较大,这样就可以保证到forget gate经常处于开放状态
- 现在还有一种网络GRU(Gate Recurrent Unit),只有两个Gate,所以参数相对于LSTM较少,可以防止overfitting。具体来说它是将Input Gate和Forget Gate联动起来,当Input Gate被打开时,Forget Gate自动关闭忘记memory中的信息;当Forget Gate打开时,Input Gate关闭,只要memory里面的值,也就是说只有把memory里面的值”清洗“掉,新的值才会被放进来。
- 还有很多其他的方法避免gradient vanish:比如**Clockwise RNN、Structurally Constrained Recurrent Network(SCRN)**等等