Bug in TensorBoardLogger add_hparams() #2023
Labels
help wanted
Open to be worked on
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Issue
Hyper parameters will not shown in the Tensorboard when using the TensorBoardLogger().
Bug identification
I am trying to use the add_hparams() function to tune my network. Using the sample code provided in PyTorch, I have no problem to view the hyper parameters and the associated accuracy / loss in the tensorboard. The code is shown below
But the same code will not work (50% of the time) when I call this code inside the Lightning module. I will explain what the rest of 50% chance is later. The code is shown below. By calling this code alone, I get the following output, guaranteed.
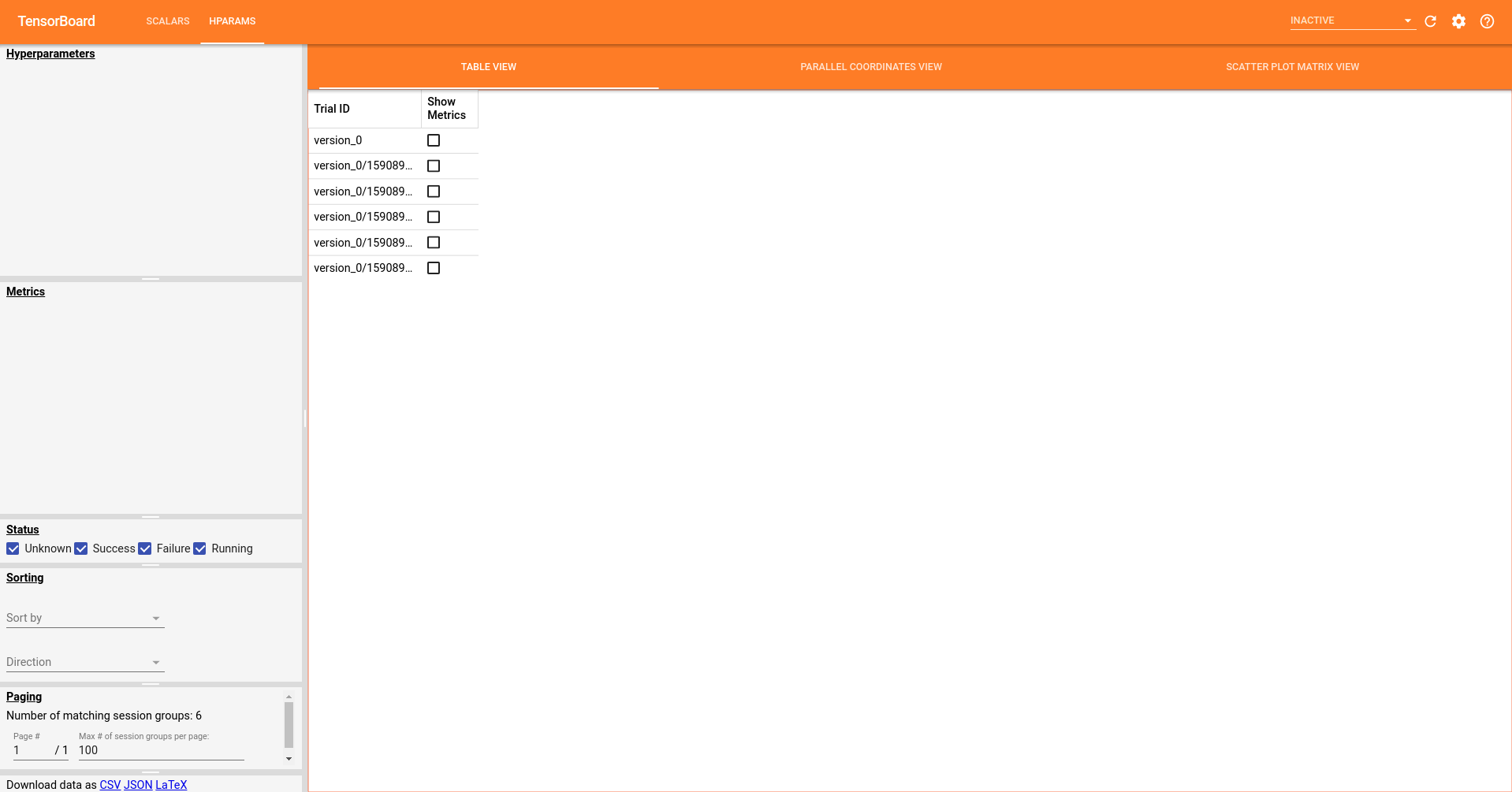
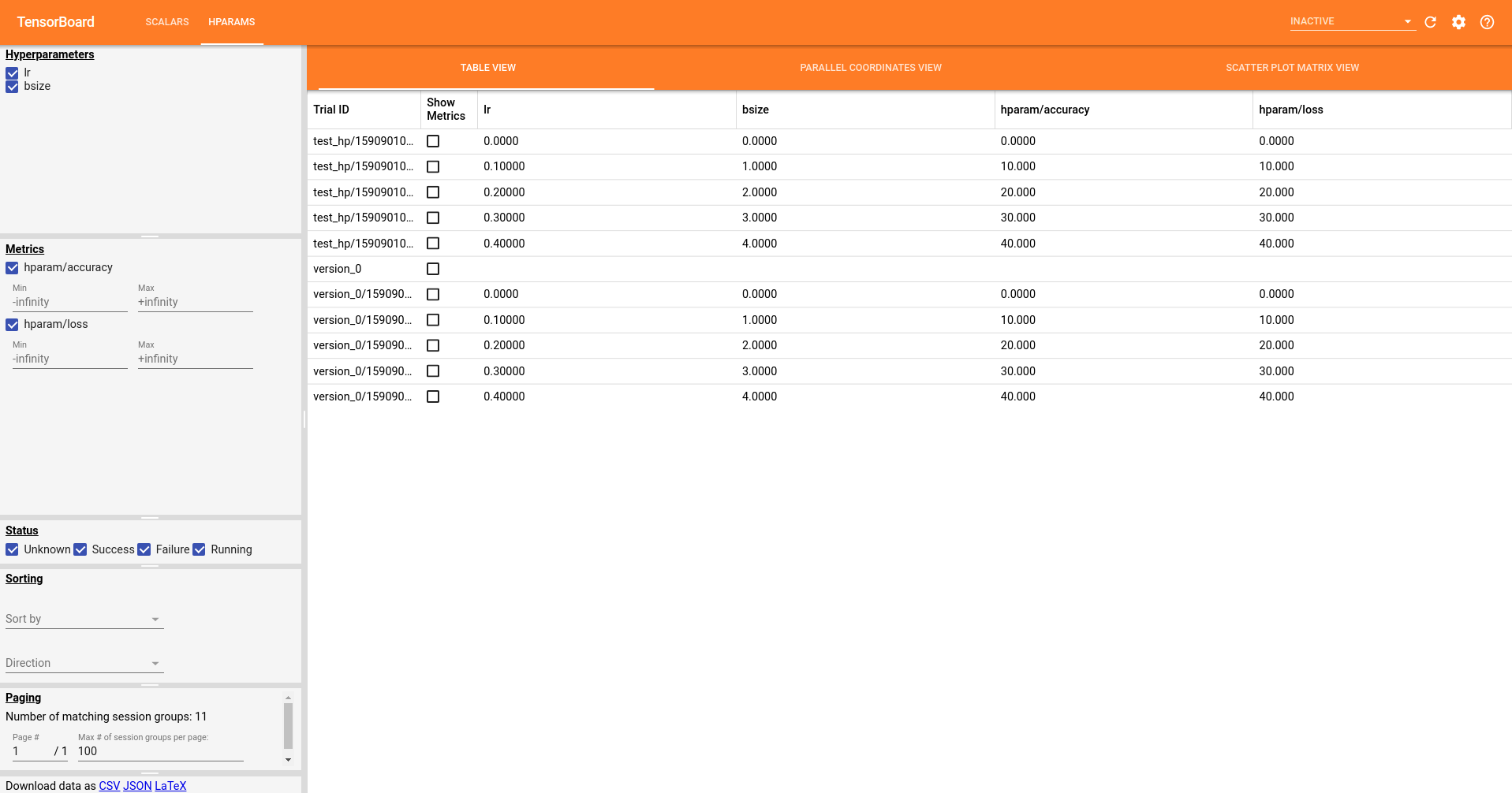
However, I discover that if I first call my first script, then call the second script. i.e. create the "test_hp" folder first, then create the "version_0" folder. I can see the hyperparameters in the tensorboard. Very weird. And now, if you delete the "test_hp" folder, the hyperparameters disappear again (back to the previous image). So it seems like the hyperparameters logged inside the Lightning model, is dependent on the data generated by the original PyTorch code. Otherwise, it cannot display properly, even we are using the same code. Is this a bug?
Environment
The text was updated successfully, but these errors were encountered: