There is a robot on an m x n grid. The robot is initially located at the top-left corner (i.e., grid[0][0]). The robot tries to move to the bottom-right corner (i.e., grid[m - 1][n - 1]). The robot can only move either down or right at any point in time.
Given the two integers m and n, return the number of possible unique paths that the robot can take to reach the bottom-right corner.
The test cases are generated so that the answer will be less than or equal to 2 * 109.
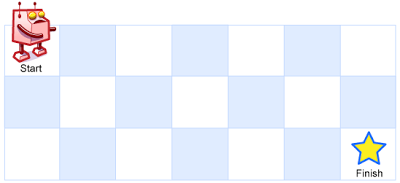
Example 1:
Input: m = 3, n = 7
Output: 28Example 2:
Input: m = 3, n = 2
Output: 3
Explanation: From the top-left corner, there are a total of 3 ways to reach the bottom-right corner:
1. Right -> Down -> Down
2. Down -> Down -> Right
3. Down -> Right -> DownTo solve this problem, I've used dynamic programming (DP). The idea is to break down the problem into smaller subproblems and solve them. We create a DP array where each element dp[i][j] represents the number of unique paths to reach the cell (i, j) from the top-left corner.
You're right. The initialization should indeed refer to the last row, given that the solution is implemented in a bottom-up way. Let's correct that and provide the detailed explanation accordingly.
-
Initialization:
- Initialize a 1D DP array
rowof sizenwith all elements set to 1. This array represents the number of ways to reach each cell in the last row, which is always 1 because there is only one way to move right to reach any cell in the last row.
- Initialize a 1D DP array
-
Filling the DP Table:
- Iterate over the rows of the grid starting from the second last row up to the first row.
- For each row, create a new DP array
newRowof sizeninitialized to 1. - Iterate over the columns of the current row from right to left. For each cell
(i, j), updatenewRow[j]to be the sum ofnewRow[j+1](number of ways to reach the cell to the right) androw[j](number of ways to reach the cell below). - Update
rowto benewRowafter processing each row.
-
Result:
- The answer is found in
row[0], which represents the number of unique paths to reach the bottom-right corner from the top-left corner.
- The answer is found in
Let's walk through the example m = 3, n = 7:
-
Initialization:
row = [1, 1, 1, 1, 1, 1, 1]
-
Iteration:
- For the first row iteration (
i = 1):newRow = [1, 1, 1, 1, 1, 1, 1]- For
j = 5to0:newRow[5] = newRow[6] + row[5] = 1 + 1 = 2newRow[4] = newRow[5] + row[4] = 2 + 1 = 3newRow[3] = newRow[4] + row[3] = 3 + 1 = 4newRow[2] = newRow[3] + row[2] = 4 + 1 = 5newRow[1] = newRow[2] + row[1] = 5 + 1 = 6newRow[0] = newRow[1] + row[0] = 6 + 1 = 7
- Update
rowtonewRow
- For the second row iteration (
i = 0):newRow = [1, 1, 1, 1, 1, 1, 1]- For
j = 5to0:newRow[5] = newRow[6] + row[5] = 1 + 2 = 3newRow[4] = newRow[5] + row[4] = 3 + 3 = 6newRow[3] = newRow[4] + row[3] = 6 + 4 = 10newRow[2] = newRow[3] + row[2] = 10 + 5 = 15newRow[1] = newRow[2] + row[1] = 15 + 6 = 21newRow[0] = newRow[1] + row[0] = 21 + 7 = 28
- Update
rowtonewRow
- For the first row iteration (
-
Result:
- The final
rowis[28, 21, 15, 10, 6, 3, 1] row[0]is28, which is the number of unique paths from the top-left to the bottom-right corner.
- The final
-
Time Complexity:
$O(m \cdot n)$ , wheremis the number of rows andnis the number of columns. We iterate through each cell of the grid once. -
Space Complexity:
$O(n)$ , wherenis the number of columns. We use a 1D DP array of sizento store the number of unique paths.
Given two strings text1 and text2, return the length of their longest common subsequence. If there is no common subsequence, return 0.
A subsequence of a string is a new string generated from the original string with some characters (can be none) deleted without changing the relative order of the remaining characters.
- For example,
"ace"is a subsequence of"abcde".
A common subsequence of two strings is a subsequence that is common to both strings.
Example 1:
Example matrix
[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]
Input: text1 = "abcde", text2 = "ace"
Output: 3
Explanation: The longest common subsequence is "ace" and its length is 3.Example 2:
Input: text1 = "abc", text2 = "abc"
Output: 3
Explanation: The longest common subsequence is "abc" and its length is 3.Example 3:
Input: text1 = "abc", text2 = "def"
Output: 0
Explanation: There is no such common subsequence, so the result is 0.This problem can be solved using dynamic programming. The idea is to create a 2D table dp where dp[i][j] represents the length of the longest common subsequence of the substrings text1[0:i] and text2[0:j].
-
DP Table Initialization:
- We initialize a 2D list
dpwith dimensions(len(text1) + 1) x (len(text2) + 1)filled with 0s. This table will help us store the lengths of LCS for substrings oftext1andtext2. - The extra row and column are to handle the case when either string is empty, in which case the LCS length is 0.
- We initialize a 2D list
-
Filling the DP Table:
- We start filling the table from the bottom-right corner.
- For each pair of indices
iandj, if the characterstext1[i]andtext2[j]match, thendp[i][j]is1 + dp[i + 1][j + 1], because the current character can be included in the LCS. - If the characters don't match, we take the maximum value between
dp[i + 1][j]anddp[i][j + 1], which represents skipping one of the characters in eithertext1ortext2.
-
Result:
- After filling the table, the top-left corner
dp[0][0]contains the length of the longest common subsequence of the two strings.
- After filling the table, the top-left corner
Let's go through the example "abcde" and "ace" in detail to understand how we can find the length of the longest common subsequence (LCS) step by step.
-
Iteration 1:
-
Start with
i = 4andj = 2(Comparingtext1[4] = "e"withtext2[2] = "e") -
The characters match (
"e" == "e"). -
Update
dp[4][2] = 1 + dp[5][3] = 1 + 0 = 1. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 2:
-
We move to
i = 4andj = 1(comparingtext1[4] = "e"withtext2[1] = "c"). -
The characters do not match (
"e" != "c"), so we cannot include this character in our common subsequence. -
To decide the value of
dp[4][1], we look at the right celldp[4][2]and the cell belowdp[5][1].dp[4][2]gives us the LCS length if we skip the current character intext2.dp[5][1]gives us the LCS length if we skip the current character intext1.
-
We take the maximum of these two values:
dp[4][1] = max(dp[4][2], dp[5][1]) = max(1, 0) = 1. -
This means that up to this point, the maximum LCS length considering these two characters remains 1.
-
The updated
dptable is:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 3:
-
Move to
i = 4andj = 0(Comparingtext1[4] = "e"withtext2[0] = "a") -
The characters do not match (
"e" != "a"). -
Update
dp[4][0] = max(dp[4][1], dp[5][0]) = max(1, 0) = 1. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 4:
-
Move to
i = 3andj = 2(Comparingtext1[3] = "d"withtext2[2] = "e") -
The characters do not match (
"d" != "e"). -
Update
dp[3][2] = max(dp[3][3], dp[4][2]) = max(0, 1) = 1. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 5:
-
Move to
i = 3andj = 1(Comparingtext1[3] = "d"withtext2[1] = "c") -
The characters do not match (
"d" != "c"). -
Update
dp[3][1] = max(dp[3][2], dp[4][1]) = max(1, 1) = 1. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [0, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 6:
-
Move to
i = 3andj = 0(Comparingtext1[3] = "d"withtext2[0] = "a") -
The characters do not match (
"d" != "a"). -
Update
dp[3][0] = max(dp[3][1], dp[4][0]) = max(1, 1) = 1. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 7:
-
Move to
i = 2andj = 2(Comparingtext1[2] = "c"withtext2[2] = "e") -
The characters do not match (
"c" != "e"). -
Update
dp[2][2] = max(dp[2][3], dp[3][2]) = max(0, 1) = 1. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 8:
-
Move to
i = 2andj = 1(Comparingtext1[2] = "c"withtext2[1] = "c") -
The characters match (
"c" == "c"). -
Update
dp[2][1] = 1 + dp[3][2] = 1 + 1 = 2. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 9:
-
Move to
i = 2andj = 0(Comparingtext1[2] = "c"withtext2[0] = "a") -
The characters do not match (
"c" != "a"). -
Update
dp[2][0] = max(dp[2][1], dp[3][0]) = max(2, 1) = 2. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 0, 0], [2, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 10:
-
Move to
i = 1andj = 2(Comparingtext1[1] = "b"withtext2[2] = "e") -
The characters do not match (
"b" != "e"). -
Update
dp[1][2] = max(dp[1][3], dp[2][2]) = max(0, 1) = 1. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 0, 1, 0], [2, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 11:
-
Move to
i = 1andj = 1(Comparingtext1[1] = "b"withtext2[1] = "c") -
The characters do not match (
"b" != "c"). -
Update
dp[1][1] = max(dp[1][2], dp[2][1]) = max(1, 2) = 2. -
The updated
dptable:dp = [[0, 0, 0, 0], [0, 2, 1, 0], [2, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 12:
-
Move to
i = 1andj = 0(Comparingtext1[1] = "b"withtext2[0] = "a") -
The characters do not match (
"b" != "a"). -
Update
dp[1][0] = max(dp[1][1], dp[2][0]) = max(2, 2) = 2. -
The updated
dptable:dp = [[0, 0, 0, 0], [2, 2, 1, 0], [2, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 13:
-
Move to
i = 0andj = 2(Comparingtext1[0] = "a"withtext2[2] = "e") -
The characters do not match (
"a" != "e"). -
Update
dp[0][2] = max(dp[0][3], dp[1][2]) = max(0, 1) = 1. -
The updated
dptable:dp = [[0, 0, 1, 0], [2, 2, 1, 0], [2, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 14:
-
Move to
i = 0andj = 1(Comparingtext1[0] = "a"withtext2[1] = "c") -
The characters do not match (
"a" != "c"). -
Update
dp[0][1] = max(dp[0][2], dp[1][1]) = max(1, 2) = 2. -
The updated
dptable:dp = [[0, 2, 1, 0], [2, 2, 1, 0], [2, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
-
Iteration 15:
-
Move to
i = 0andj = 0(Comparingtext1[0] = "a"withtext2[0] = "a") -
The characters match (
"a" == "a"). -
Update
dp[0][0] = 1 + dp[1][1] = 1 + 2 = 3. -
The final
dptable:dp = [[3, 2, 1, 0], [2, 2, 1, 0], [2, 2, 1, 0], [1, 1, 1, 0], [1, 1, 1, 0], [0, 0, 0, 0]]
-
- The value at
dp[0][0]is3, which is the length of the longest common subsequence betweentext1 = "abcde"andtext2 = "ace".
-
Time Complexity:
$O(m \times n)$ , wheremis the length oftext1andnis the length oftext2.- We need to fill a 2D table of size
m x n.
- We need to fill a 2D table of size
-
Space Complexity:
$O(m \times n)$ .- We use a 2D table to store the lengths of the longest common subsequence for each pair of indices.