A problem about relation between "openblas_set_num_threads" and CPU waste and time cost? #1544
Comments
|
I suspect without setting the number of threads it will try to use all four cores, causing conflicts with the other processes on your system (leading to rescheduling and invalidating caches). How is the performance with 2 or 3 threads (leaving one core for everybody else) ? It could also be that one of the OpenBLAS functions you use is needlessly trying to parallelize its workload, so it might be useful to know which functions you are calling, and how big your matrix sizes are. |
|
@martin-frbg Thanks for your quick reply. I print default openblas_num_thread is 4. I have make a try. When I use 2 or 3 threads, the performance it similar like thread 4. CPU and time waste is still much higher.Here is function I used: |
|
There are two old tickets on sgemv performance compared to other BLAS implementations that were never conclusively solved (mostly from lack of data it seems), #532 and #821. |
|
I just pull a version of openblas about Dec,2017, not a release version |
|
Actually my recollection was wrong, the two PRs I mentioned did not affect GEMV at all, sorry. |
|
Could you try to record source of waste with 'perf record' and 'perf report' and paste top page from later? |
|
Running the perf report for this benchmark is dominated by the calls to random() used to set up the matrix, but at least the mutex lock/unlock calls seem to make an insignificant contribution compared to the gemv kernel operations. Due to the fixed 2GB memory of the tinkerboard, the upper limit for the matrix size is around 21000x21000. |
|
Thanks for your kind reply @martin-frbg . Actually,time cost is real have much influence for me. I want to use much small cpu waste because my limit of my hardware, so Is there some parameters for me to reduce cpu waste? Need I have rebuild it? |
|
I did not find a problem with the test, perhaps there is something special about your program that makes it behave differently than the gemv.goto benchmark. |
|
I do not see anything suspicious with xianyi's dgemv test case from #532 (comment) either (running with either "6000 128" or "128 6000" for 1000 iterations each). Unlikely that using cblas_sgemv instead of sgemv adds that much overhead to cause your problem. Perhaps retry with current 0.3.0 release ? |
|
I think the difference is from when you cross compile. Did you cross compile for test on tinker board? |
|
Good point, I compile locally. (I do see an improvement now with oon3m0oo's recent commit that cleaned up the memory initialization on thread startup, so sunbinbin1991 may want to try the current |
|
As for my problem, most of possible reason is limitation of my hardware. In my project not only openblas is running, also, some other application is still on, maybe this is reason when I use "multi-thread" could waste much more time. Actually, even “openblas_set_num_threads = 1“, my matrix calculate is waste less than 1ms, that's enough for me.
here is my result:
|
First, I will introduce ,my background. I have to accelerate a matrix calculation. My hardware is RK3288 which have four Quad-Core Cortex-A17 cpu. When I use it by default,

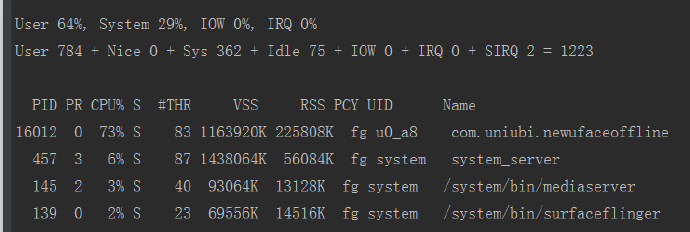
it is waste much more time to calculate, and waste much CPU,as below,
cpu cost:
however, when I set the openblas_num_threads,like this:
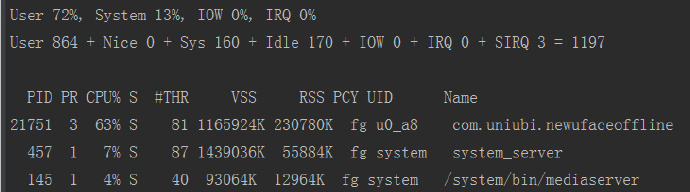
openblas_set_num_threads(1);I found, it waste not much time and CPU waste is much lower,as below,
cpu cost:
clearly, waste time and cpu waste both reduced. So, what happen for this problem?
The text was updated successfully, but these errors were encountered: