Official inference code for the Web-SSL model family introduced in: Scaling Language-Free Visual Representation Learning.
David Fan*, Shengbang Tong*, Jiachen Zhu, Koustuv Sinha, Zhuang Liu, Xinlei Chen, Michael Rabbat, Nicolas Ballas, Yann LeCun, Amir Bar†, Saining Xie†
FAIR Meta, New York University, Princeton University
*equal contribution, †equal advising
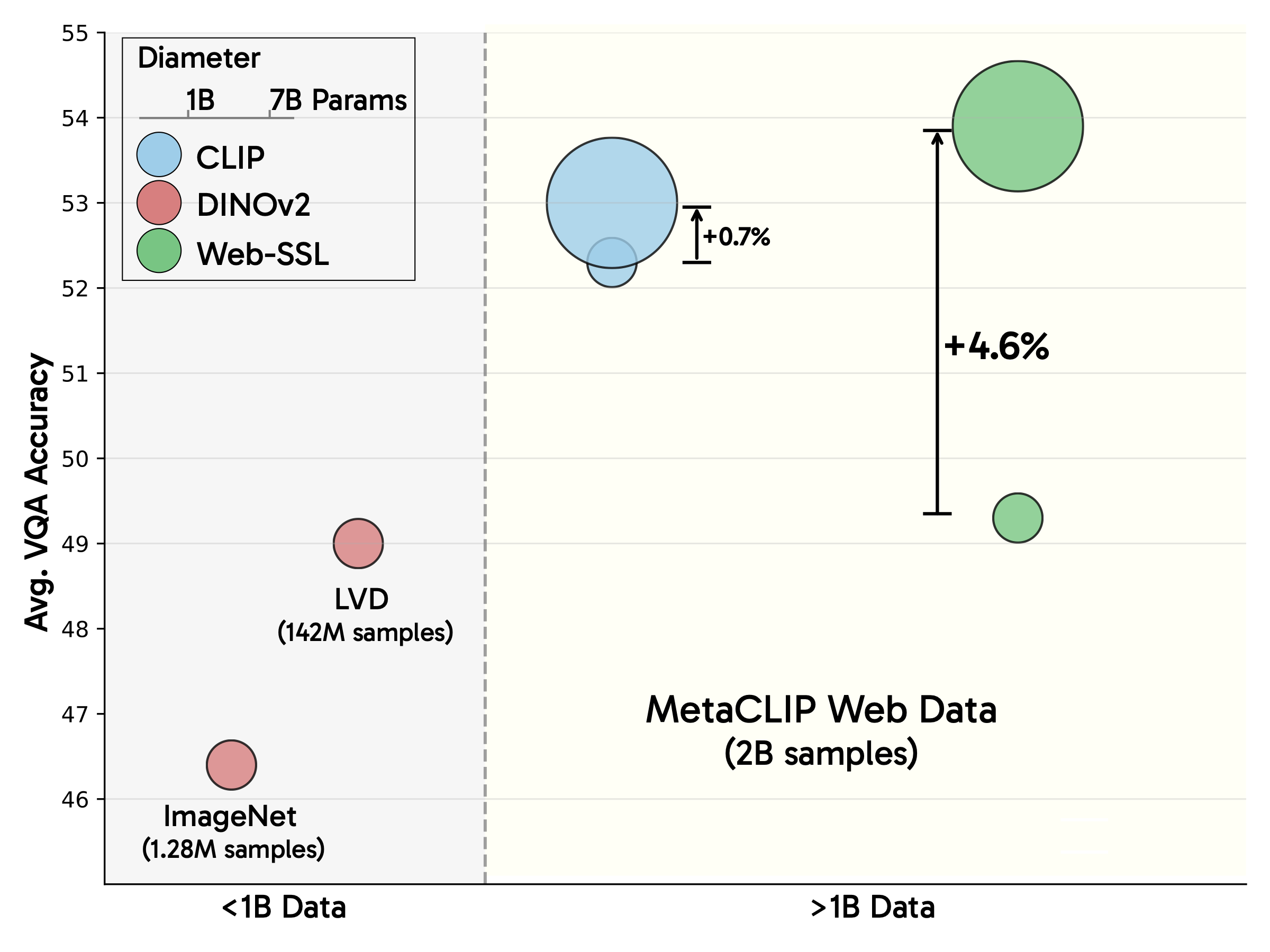
Web-SSL explores the scaling potential of visual self-supervised learning (SSL) on web-scale data. By scaling model size and training data, we show that vision-only models can match and even surpass language-supervised methods like CLIP, challenging the prevailing assumption that language supervision is necessary to learn strong visual representations for multimodal modeling. We present Web-SSL: a family of vision-only models, ranging from 0.3B to 7B parameters, that offers a strong alternative to CLIP for both multimodal modeling and classic vision tasks.
Key findings:
- 📈 SSL improves continuously with both model capacity and data.
- 🔍 Web-SSL matches or exceeds language-supervised methods on a wide range of VQA tasks—even on language-related tasks like OCR & Chart understanding, which were traditionally dominated by CLIP.
- 🖼️ Our models maintain competitive performance on classic vision tasks like classification and segmentation while excelling at multimodal tasks.
- 📊 Visual SSL methods are sensitive to data distribution! Training on filtered datasets with a higher concentration of text-rich images substantially improves OCR & Chart understanding.
We provide our model weights in both HuggingFace and native PyTorch format. Please see the Usage section for sample model loading and inference code.
Web-DINO is a family of DINOv2 models ranging from 0.3B to 7B parameters trained on larger scale web images. Web-DINO models especially excel at multimodal tasks such as VQA, without sacrificing performance in classic vision tasks such as image classification. Please see our paper for full details.
| Model | Patch Size | Resolution | Data | HuggingFace | Weights |
|---|---|---|---|---|---|
| webssl-dino300m-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino1b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino2b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino3b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino5b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-dino7b-full8b-224 ⭐ | 14x14 | 224x224 | 8B (MC-2B) | Link | Link |
| webssl-dino7b-full8b-378 ⭐ | 14x14 | 378x378 | 8B (MC-2B) | Link | Link |
| webssl-dino7b-full8b-518 ⭐ | 14x14 | 518x518 | 8B (MC-2B) | Link | Link |
Model Notes:
- webssl-dino7b-full8b-224 ⭐: Best 224x224 resolution model
- webssl-dino7b-full8b-378 ⭐: Better performance with 378x378 resolution
- webssl-dino7b-full8b-518 ⭐: Best overall performance with 518x518 resolution
These models were trained on filtered subsets of MC-2B images with a higher concentration of text (e.g. signs, charts, tables, annotations, etc). This enhances OCR & Chart understanding capabilities without a notable performance drop in other VQA categories, relative to same-size models trained on the full data.
| Model | Patch Size | Resolution | Data | HuggingFace | Weights |
|---|---|---|---|---|---|
| webssl-dino2b-light2b-224 | 14x14 | 224x224 | 2B (MC-2B light) | Link | Link |
| webssl-dino2b-heavy2b-224 | 14x14 | 224x224 | 2B (MC-2B heavy) | Link | Link |
| webssl-dino3b-light2b-224 | 14x14 | 224x224 | 2B (MC-2B light) | Link | Link |
| webssl-dino3b-heavy2b-224 | 14x14 | 224x224 | 2B (MC-2B heavy) | Link | Link |
Data Notes:
- MC-2B light: 50.3% subset of MC-2B images that contain text
- MC-2B heavy: 1.3% subset of MC-2B images that contain charts/documents
Web-MAE is a family of MAE models ranging from 0.3B to 3B parameters, trained on larger scale web images. We release only the encoder for feature extraction.
| Model | Patch Size | Resolution | Data | HuggingFace | Weights |
|---|---|---|---|---|---|
| webssl-mae300m-full2b-224 | 16x16 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae700m-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae1b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae2b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
| webssl-mae3b-full2b-224 | 14x14 | 224x224 | 2B (MC-2B) | Link | Link |
In response to community feedback, we are open-sourcing a few add-ons that are not part of the official release. Please see ADDITIONAL_MODELS.md for more details.
It is possible that older or newer versions will work. However, we haven't tested them for this inference code.
conda create -n webssl python=3.11
conda activate webssl
pip install torch==2.5.1 torchvision==0.20.1 xformers --index-url https://download.pytorch.org/whl/cu124
pip install transformers==4.48.0 huggingface-hub==0.27.1 timm==1.0.15
We provide two examples to use our models with both HuggingFace and native PyTorch. Note that you are not limited to using the pretraining resolution for inference, however, you will probably get the best results by inferencing with the same resolution.
You may choose to download the model weights locally first using huggingface-cli. This is convenient when you don't have a large cache or when the network is slow.
E.g. huggingface-cli download facebook/webssl-dino7b-full8b-518 --local-dir YOUR_PATH, then supply YOUR_PATH to from_pretrained().
from transformers import AutoImageProcessor, Dinov2Model
# Load a Web-DINO model
model_name = "facebook/webssl-dino1b-full2b-224"
processor = AutoImageProcessor.from_pretrained(model_name)
model = Dinov2Model.from_pretrained(model_name, attn_implementation='sdpa') # 'eager' attention also supported
model.cuda().eval()
# Process an image
from PIL import Image
image = Image.open("sample_images/bird.JPEG")
with torch.no_grad():
inputs = processor(images=image, return_tensors="pt").to('cuda')
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_statefrom dinov2.vision_transformer import webssl_dino1b_full2b_224
import torch
from PIL import Image
from torchvision import transforms
# Define image transformation
transform = transforms.Compose([
transforms.Resize(256, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
# Load model
model = webssl_dino1b_full2b_224()
# Load weights
checkpoint_path = "path/to/downloaded/weights.pth"
state_dict = torch.load(checkpoint_path, map_location="cpu")
msg = model.load_state_dict(state_dict, strict=False)
print(f"Loaded weights: {msg}")
model.cuda().eval()
# Process an image
image = Image.open("sample_images/bird.JPEG")
x = transform(image).unsqueeze(0).cuda()
with torch.no_grad():
features = model.forward_features(x)
patch_features = features['x_norm_patchtokens']See demo_webdino.py and demo_webmae.py for a complete example comparing HuggingFace and PyTorch implementations.
If you find this repository useful for your research, please consider citing:
@article{fan2025scaling,
title={Scaling Language-Free Visual Representation Learning},
author={Fan, David and Tong, Shengbang and Zhu, Jiachen and Sinha, Koustuv and Liu, Zhuang and Chen, Xinlei and Rabbat, Michael and Ballas, Nicolas and LeCun, Yann and Bar, Amir and others},
journal={arXiv preprint arXiv:2504.01017},
year={2025}
}The majority of Web-SSL is licensed under CC-BY-NC, however portions of the project are available under separate license terms: DINOv2 is licensed under the Apache 2.0 license.
We thank the DINOv2 and MAE teams for their excellent codebases, and the MetaCLIP team for the wonderful MetaCLIP dataset and codebase. We thank the Cambrian team for their insightful study into the role of vision encoders in MLLMs and their evaluation suite. Lastly, we thank our amazing collaborators in FAIR and the Meta Open-Source team for making this possible.