Regular object layout #80
Comments
|
Since not all objects have a Since any object that has a dictionary can be part of a cycle, it must have a GC header. Simple object without GC header, e.g. an int.
Object that may be part of cycle, but without
|


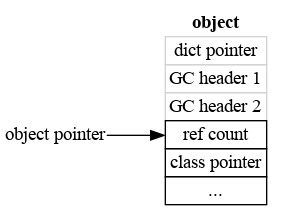
|
pymalloc aligns memory blocks with 2words (8byte on 32bit, 16byte on 64bit platform). Currently, GC header is 2 words so no gap. If we add |
|
If we were to reduce the GC header to a single word, then placing the dict pointer before the header would be even more compelling as it would fill the gap. |
|
Given that allocations are two-word aligned, the pre-header needs to be an even number of words. Long term we want this layout:
But in the medium term, this gives us fixed offsets for dict and weakref pointers and is as compact as what we have now:
|


|
Maybe a noobish and/or off-topic question because I don't know much about CPython memory layout, but why is there anything before what the object pointer points to at all? Why not just keep it all after that? |
|
It needs to be at a fixed offset and allow for variable sized objects and inheritance. |
|
In particular, for ABI compatibility we need to keep ob_refcnt and ob_type at the same offset relative to the pointer. |
|
An alternative to the above, which will work well with #72 (comment) is: |

|
Regular object layout would also help the GC traverse and clean objects, as well as simplify code for inheritance of layouts, assigning I'm going to gloss over weak references here. If we inline the values, the weakref list can go where the values pointer is now. The object can be broken down into five sections:
The first three are described above. The custom section is whatever is handled by the custom code for a builtin class. Slots are slots described either by E.g. the following class class XList(list):
__slots__ = "a", "b", "__dict__"would have all five sections. In contrast, Objects without a custom section, are transparent to the GC and VM and will need no custom InheritanceThe rules for layout inheritance are much as they are now, but slightly simplifies by having the dictionary at a fixed offset. Multiple inheritance where more than one class has a custom section is prohibited. I think this is the same as it is now: "multiple bases have instance lay-out conflict". GC operationsThe GC needs to traverse objects and clear them. In addition, objects need to be deallocated. For objects without a custom section (and perhaps for some special cases with a custom section) the above layout is transparent to the GC. The traversal and deallocation functions can be inlined leading to faster and more robust memory management. |
|
So the slots section is not used for "ordinary attributes" (the ones that go into For a tuple, would the custom section contain everything, or would the custom section only contain the length so the items would become slots? (That would be handy for namedtuples too.) But this seems to contradict the idea that the layout would be transparent to the GC -- it would have to know to look in the custom section to find how many slots there are. I worry about backwards compatibility here -- 3rd party type definitions should remain supported (probably for many releases). I also worry specifically about |
|
"Custom" can contain anything. Fully backwards compatible and opaque to the GC. Code that sets Code that uses Which means that we can't use regular object layout for classes that inherit from For example, this class: class XTuple(tuple):
passwould not be able to have the |
|
I think this is done. We might want to tweak this later, but that can be its own issue. |
Accessing the
__dict__of an object takes a bit of pointer chasing and computation.The code to get the address of the
__dict__is as follows:(assuming we have already checked whether this object can have a dict)
Given how often we access instance attributes, this overhead is significant
What we would like is:
The text was updated successfully, but these errors were encountered: