Initial round of probability distributions and statistical functions #240
Conversation
Initial implementation of probability distributions and statistical functions
|
Realized the Fortran standard functions 'random_seed' and 'random_number' may not have the same algorithm on different platforms and OS. Will update the random number generator. TODO: modify the random_seed function to avoid using standard random_number function call |
|
Thanks a lot @Jim-215-Fisher! I will review it. On first look I only noticed two things:
as they don't add value. I know, this is not mentioned in the style guide yet. Good rule of thumb is to just mimic the style of existing modules. More later. |
|
The |
Ah, okay, I didn't realize. I think this is fine if it extends the intrinsic one while preserving the original behavior. |
|
Thank you @Jim-215-Fisher for this PR. I will try to review it this week. |
src/stdlib_stats_distribution.fypp
Outdated
| !--------------------------------------------------------------------------------------------- | ||
| ! Uniform Distribution | ||
| !--------------------------------------------------------------------------------------------- |
There was a problem hiding this comment.
| !--------------------------------------------------------------------------------------------- | |
| ! Uniform Distribution | |
| !--------------------------------------------------------------------------------------------- |
There was a problem hiding this comment.
as per @milancurcic , these separators add no value and is not in style, will remove in the next round.
|
Just load modified version. 1)add 64bit random integer generator code, 2) modified |
|
It looks like ubuntu platform does not like submodule, gcc7, 8 and 9 all show the same error: buffer overflow. |
There was a problem hiding this comment.
Could it be that your hexadecimal constants are overflowing the int64 kind?
With gfortran you might need the flag -fno-range-check in that case (see here: #214 (comment)).
|
I noticed that issue. I have changed that part into regular negative decimal. Right now, file stats_distribution_rv and stats_distribution have passed compilation, but stats_distribution_implementation fail to compile on ubuntu. The same file has passed on windows and Mac. |
|
This is likely a bug on gcc. See Bug 91773 - Buffer overflow for long module/submodule names |
clean up for stdlib_stats_distribution_rvs.fypp
Changed the implementation submodule name to `stdlib_stats_distribution_imp`
…_implementation.o to stdlib_stats_distribution_imp.o
There was a problem hiding this comment.
Thank you for this PR. Here are some comments on the specs.
Since there are mainly 3 very similar (in ternms of API) parts (uniform, norm, and binomial), I am wondering if it would not be easier to submit/review 3 different small PRs instead of this large one. What is your opinion @certik @milancurcic @ivan-pi ?
Meanwhile I will first focus on the uniform part.
|
|
||
| The probability density function of the continuous uniform distribution. | ||
|
|
||
| 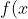=\begin{cases}\frac{1}{scale}&loc\leqslant&space;x<loc+scale\\\\0&x<loc,or,x>loc+scale\end{cases}) |
There was a problem hiding this comment.
FORD supports Latex: see here for more details.
Something like (I didn't check the formula):
| 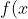=\begin{cases}\frac{1}{scale}&loc\leqslant&space;x<loc+scale\\\\0&x<loc,or,x>loc+scale\end{cases}) | |
| \( \frac{1}{scale}&loc\leqslant&space;x<loc+scale\\\\0&x<loc,or,x>loc+scale )\ |
There was a problem hiding this comment.
FORD supports Latex: see here for more details.
Something like (I didn't check the formula):
I tried FORD LaTex support, It seems not working for my formulae.
There was a problem hiding this comment.
Ok. Thanks for trying. I will try it later too. IMO it is preferable to not rely on a third party app.
|
|
||
| Experimental | ||
|
|
||
| ### Description |
There was a problem hiding this comment.
Would it be possible to return an muti-dimension array (e.g., a ran-3 array), e.g., as in Matlab
There was a problem hiding this comment.
Would it be possible to return an muti-dimension array (e.g., a ran-3 array), e.g., as in Matlab
Yes. the functions are elemental except the the random number generators, they should work on multi-dimension arrays.
There was a problem hiding this comment.
It would be nice that the random number generator functions ("_rvs") also support arrays up to rank 7 or 15 (depending on the compiler). This could be easily generated with Fypp (maybe in a next PR?).
There was a problem hiding this comment.
random number generator function itself has no issue with array support, it is elemental. The problem is how to initiate the function call. Normally, one uses one set of parameters to get either one or an array of random numbers. This is how current implementation worked. If we want array support up to rank 15, then we need a mask array as an optional argument to the function call. If peoples like the idea, we can certainly implement it next round.
There was a problem hiding this comment.
I was thinking to extend the rank-1 function to multiple ranks, e.g. with multiple loops. Therefore, there is no need for optional arguments (there would rank+1 different procedures). But, as you mentioned, we can think about that in a next round if desired.
These three are just the initial part of whole statistical distributions, there are more distributions coming. All of them have similar API. |
Co-authored-by: Jeremie Vandenplas <[email protected]>
Co-authored-by: Jeremie Vandenplas <[email protected]>
Co-authored-by: Jeremie Vandenplas <[email protected]>
Co-authored-by: Jeremie Vandenplas <[email protected]>
Co-authored-by: Jeremie Vandenplas <[email protected]>
|
Just for your information you should use algorithms avoiding floating-point arithmetic when possible (or at least make such implementations an option). For example, there are algorithms of the exponential distribution that use comparisons only (von Neumann's method, for one) as well as exact samplers of the Binomial distribution (e.g., Farach-Colton and Tsai, "Exact Sublinear Binomial Sampling"; the "Internal DLA" paper by Bringmann and others). Even the Poisson distribution can be sampled without using the exponential function (e.g. "On Buffon Machines and Numbers"). Perhaps the most familiar example of a distribution of this kind is the discrete (and continuous) normal distribution sampler by Karney. See also my section on "Specific Non-Uniform Distributions" in "Randomization and Sampling Methods". In fact, as the authors of "Exact Sublinear Binomial Sampling" found, BTPE can oversample the tail of a binomial distribution (or at least the GNU Scientific Library implementation of BTPE at the time of the paper can). For a simpler description of the Bringmann algorithm, see my page "Miscellaneous Observations on Randomization". |
Thanks for the info. I will take a look of it. |
|
I am going to update for the second round. Because of major change in module structure, should I initiate a new PR or just continue in this old one? |
Does the new changes contain the same info? If yes, I suggest to update this PR. |
Instead of one big module plus one submodule structure, I split the statistical distributions into each individual module, which will be easier to maintain. Also, in the new update, it will contain more distributions and new function calls. |
Thank you for the details. Following your description, I would propose that you submit one PR per module, if possible. It would be easier to review than a very long PR. |
This is the first round of probability distributions and statistical functions. Anyone is welcomed to review it. The following source files were added:
src/stats_distribution_rvs.fypp
src/stats_distribution.fypp
src/stats_distribution_implementation.fypp
The specs documentation was added:
doc/specs/stdlib_stats_distribution.md
The test program was added:
src/tests/stats/test_distribution.f90
The following compilation files were modified:
src/CMakeLists.txt
src/Makefile.manual
src/tests/stats/CMakeLists.txt
src/tests/stats/Makefile.manual
doc/specs/index.md